
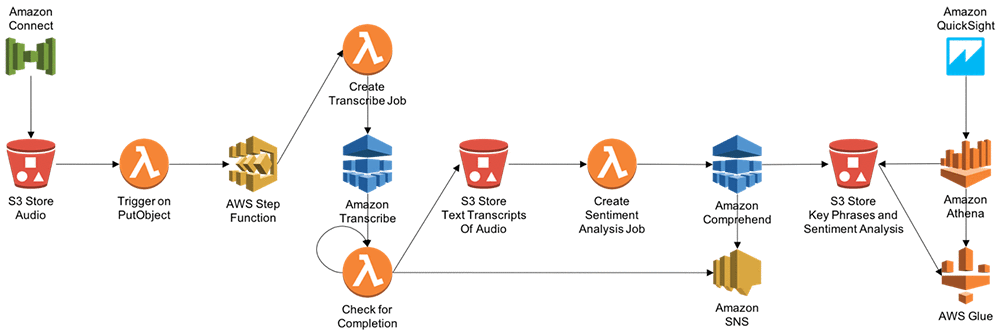
As businesses continue to evolve and customer expectations continue to rise, analyzing customer sentiment has become a crucial aspect of success. Analyzing customer sentiment can help businesses understand how customers feel about their products and services, identify areas for improvement, and develop strategies to enhance the customer experience. In this two-part blog series, we will explore how to analyze contact center calls using Amazon Transcribe and Amazon Comprehend to analyze customer sentiment.
Transcribe call center audio, run sentiment analysis, and visualize analytics
After uploading audio files to an Amazon S3 bucket, we’ll trigger a Lambda function to invoke Step Functions that will point the Amazon Transcribe service to the bucket destination to create transcription jobs. Accepted audio/visual formats include: WAV, FLAC, MP3, and MP4.
Procedure
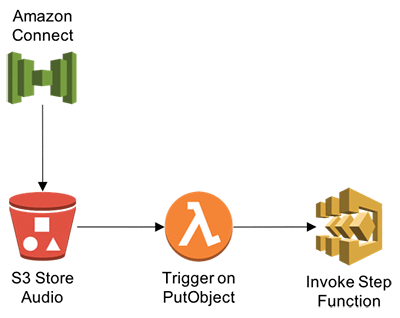
Step 1: Create the Lambda function and IAM policy
- Open the AWS Management Console and navigate to the Lambda console. Then choose Create a Lambda function.
- Choose Skip to skip the blueprint selection.
- For Runtime, choose Node JS 8.10.
- For Name, enter a function name.
- Enter a description that notes the source bucket and destination bucket used.
- For Code entry type, choose Edit code inline.
- Create environment variable – STEP_FUNCTIONS_ARN
- Paste the following into the code editor:
'use strict';
const aws = require('aws-sdk');
var stepfunctions = new aws.StepFunctions();
const s3 = new aws.S3({apiVersion: '2006-03-01'});
exports.handler = (event, context, callback) => {
const bucket = event.Records[0].s3.bucket.name;
const key = decodeURIComponent(event.Records[0].s3.object.key.replace(/\+/g, ' '));
const params = {Bucket: bucket,Key: key};
s3.getObject(params, (err, data) => {
if (err) {
console.log(err);
const message = `Error getting object ${key} from bucket ${bucket}. Make sure they exist and your bucket is in the same region as this function.`;
console.log(message);
callback(message);
} else {
var job_name = key.replace("/", "-");
var stepparams = {
"stateMachineArn": process.env.STEP_FUNCTIONS_ARN,
"input": "{\"s3URL\": \"https://s3.amazonaws.com/" + bucket + "/" + key + "\",\"JOB_NAME\": \""+ job_name + "\"}"
};
stepfunctions.startExecution(stepparams, function(err, data) {
if (err) console.log(err, err.stack); // an error occurred
else console.log(data); // successful response
});
callback(null, data.ContentType);
}
});
};Step 2: Create source Amazon S3 bucket
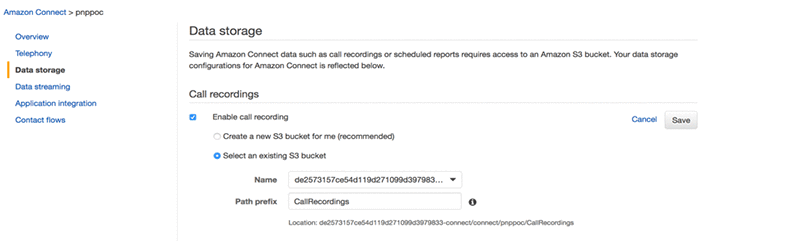
- Navigate to the Amazon S3 console and edit the source bucket configuration.
- Expand the Events section and provide a name for the new event.
- For Events, choose ObjectCreated (ALL).
- For Send to, choose Lambda Functions.
- For Lambda Function, select the Lambda function name you chose in Step 1.
- Choose Save
Step 3: Create Transcribe and Comprehend APIs using a Lambda function
- Trigger Transcribe job based on the input S3 audio transcript received. Two parameters are received – s3URL and JOB name.
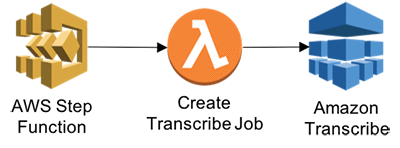
- Navigate to the Lambda console, and then choose Create a Lambda function.
- Choose Skip to skip the blueprint selection.
- For Runtime, choose Node JS 8.10.
- For Name, enter a function name.
- Enter a description that notes Create Transcribe JOB based on the input received.
- For Code entry type, choose Edit code inline.
- Paste the following into the code editor
var AWS = require('aws-sdk');
var transcribeservice = new AWS.TranscribeService();
exports.handler = (event, context, callback) => {
var params = {
LanguageCode: 'en-US',
Media: { /* required */
MediaFileUri: event.s3URL + ""
},
MediaFormat: 'mp3',
TranscriptionJobName: event.JOB_NAME
};
transcribeservice.startTranscriptionJob(params, function(err, data) {
if (err) console.log(err, err.stack); // an error occurred
else {
console.log(data); // successful response
event.wait_time = 60;
event.JOB_NAME = data.TranscriptionJob.TranscriptionJobName;
callback(null, event);
}
});
};Step 4: Get Transcribe Job Status
- Get transcribed JOB status. This function will enable Step functions to wait for transcribe job to complete.
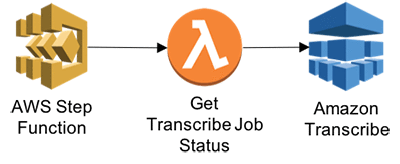
- In the Lambda console, choose Create a Lambda function.
- Choose Skip to skip the blueprint selection.
- For Runtime, choose Node JS 8.10.
- For Name, enter a function name.
- Enter a description that notes Transcribe JOB details.
- For Code entry type, choose Edit code inline.
- Paste the following into the code editor:
var AWS = require('aws-sdk');
var transcribeservice = new AWS.TranscribeService();
exports.handler = (event, context, callback) => {
var params = {
TranscriptionJobName: event.JOB_NAME /* required */
};
transcribeservice.getTranscriptionJob(params, function(err, data) {
if (err) console.log(err, err.stack); // an error occurred
else console.log(data); // successful response
event.STATUS = data.TranscriptionJob.TranscriptionJobStatus;
event.Transcript =data.TranscriptionJob.Transcript;
callback(null,event);
});
};Step 5: Get transcribe job details
- This function will enable Step Functions to get transcribe JOB details once completed.
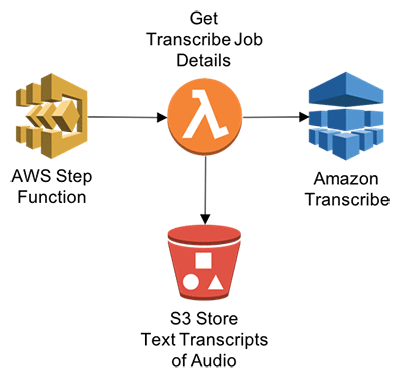
- In the Lambda console, choose Create a Lambda function.
- Choose Skip to skip the blueprint selection.
- For Runtime, choose Node JS 8.10.
- For Name, enter a function name.
- Enter a description that notes get information about the transcribe job.
- For Code entry type, choose Edit code inline.
- Paste the following into the code editor:
var AWS = require('aws-sdk');
var transcribeservice = new AWS.TranscribeService();
exports.handler = (event, context, callback) => {
var params = {
TranscriptionJobName: event.JOB_NAME /* required */
};
transcribeservice.getTranscriptionJob(params, function(err, data) {
if (err) console.log(err, err.stack); // an error occurred
else console.log(data); // successful response
event.STATUS = data.TranscriptionJob.TranscriptionJobStatus;
event.TranscriptFileUri =data.TranscriptionJob.Transcript.TranscriptFileUri;
callback(null,event);
});
};Step 6: Call Amazon Comprehend to analyze transcription text
- In this step, you’ll get transcribed audio text and perform contextual analysis. This function will enable Step Functions to call Amazon Comprehend to perform sentiment analysis.
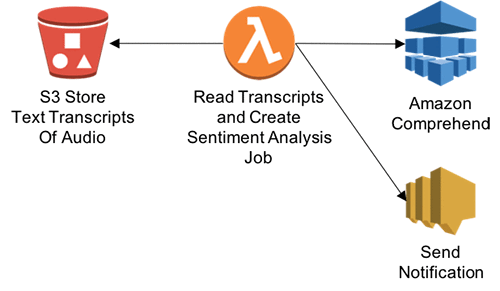
- In the Lambda console, choose Create a Lambda function.
- Choose Skip to skip the blueprint selection.
- For Runtime, choose Node JS 8.10.
- For Name, enter a function name.
- Enter a description that notes get information about the transcribe job.
- For Code entry type, choose Edit code inline.
- Paste the following into the code editor :
var https = require('https');
let AWS = require('aws-sdk');
var comprehend = new AWS.Comprehend({apiVersion: '2017-11-27'});
exports.handler = function(event, context, callback) {
var request_url = event.TranscriptFileUri;
https.get(request_url, (res) => {
var chunks = [];
res.on("data", function (chunk) {
chunks.push(chunk);
});
res.on("end", function () {
var body = Buffer.concat(chunks);
var results = JSON.parse(body);
console.log( body.toString());
var transcript = results.results.transcripts[0].transcript;
console.log(transcript)
var params = {
LanguageCode: "en",
Text: transcript + ""Step 7: Invoke Step Functions
- In this step you will leverage AWS Steps Functions orchestrate the Lambda functions created earlier and notify the end customer about the contextual analysis.
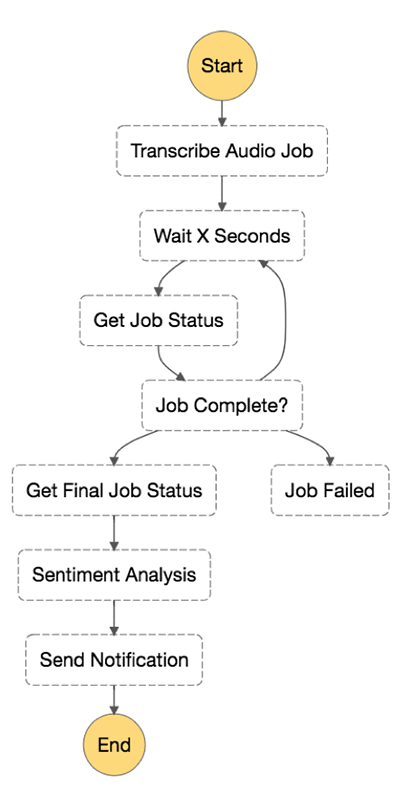
- In the Step Functions console, choose Create a state machine.
- Choose Author from scratch
- For Name, Enter your State Machine Name For example : TranscribeJob.
- Paste the following code in State machine definition
- Update the ARN values of lambda functions created in earlier steps in the State machine definition code
- Click Next
- Choose existing role which has permissions to invoke lambda functions, send SNS (Create the custom role if the role doesn’t exists)
- Click Create state machine
{
"Comment": "A state machine that submits a Job to AWS Batch and monitors the Job until it completes.",
"StartAt": "Transcribe Audio Job",
"States": {
"Transcribe Audio Job": {
"Type": "Task",
"Resource": "<<Start Transcribe job for Audio to Text ARN>>",
"ResultPath": "$",
"Next": "Wait X Seconds",
"Retry": [{
"ErrorEquals": ["States.ALL"],
"IntervalSeconds": 1,
"MaxAttempts": 3,
"BackoffRate": 2
}]
},
"Wait X Seconds": {
"Type": "Wait",
"SecondsPath": "$.wait_time",
"Next": "Get Job Status"
},
"Get Job Status": {
"Type": "Task",
"Resource": "<<Get Transcribe job status ARN>>",
"Next": "Job Complete?",
"InputPath": "$",
"ResultPath": "$",
"Retry": [{
"ErrorEquals": ["States.ALL"],
"IntervalSeconds": 1,
"MaxAttempts": 3,
"BackoffRate": 2
}]
},
"Job Complete?": {
"Type": "Choice",
"Choices": [{
"Variable": "$.STATUS",
"StringEquals": "IN_PROGRESS",
"Next": "Wait X Seconds"
}, {
"Variable": "$.STATUS",
"StringEquals": "COMPLETED",
"Next": "Get Final Job Status"
}, {
"Variable": "$.STATUS",
"StringEquals": "FAILED",
"Next": "Job Failed"
}],
"Default": "Wait X Seconds"
},
"Job Failed": {
"Type": "Fail",
"Cause": "AWS Batch Job Failed",
"Error": "DescribeJob returned FAILED"
},
"Get Final Job Status": {
"Type": "Task",
"Resource": "<<Get Transcribe job details ARN>>",
"InputPath": "$",
"Next": "Send contextual analysis"
"Retry": [{
"ErrorEquals": ["States.ALL"],
"IntervalSeconds": 1,
"MaxAttempts": 3,
"BackoffRate": 2
}]
},
"Send contextual analysis": {
"Type": "Task",
"Resource": "<<Send Contextual Analysis ARN>>",
"InputPath": "$",
"End": true,
"Retry": [{
"ErrorEquals": ["States.ALL"],
"IntervalSeconds": 1,
"MaxAttempts": 3,
"BackoffRate": 2
}]
}
}
}Step 8: Create an AWS Glue database for visualization
- Navigate to the AWS Glue console and create a database to store sentiment analysis entities.
- Add the AWS Glue table to the database you just created.
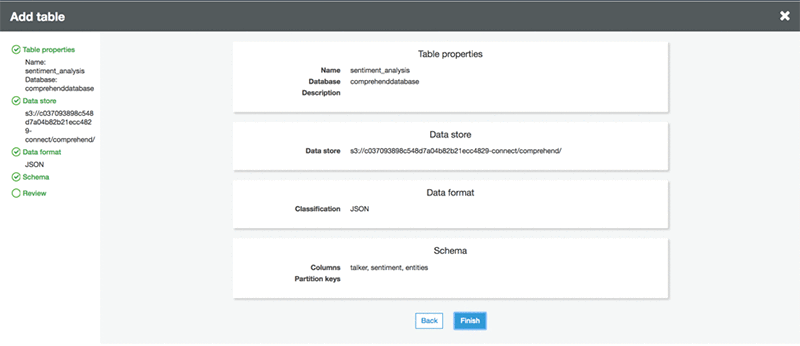
- A created table in database looks like this:
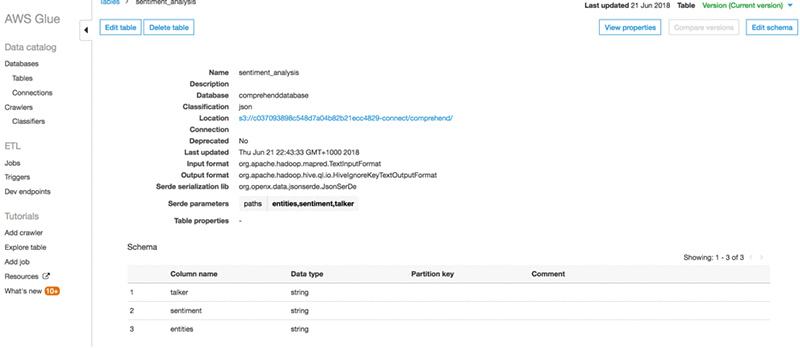
Step 9: Visualization using Amazon QuickSight
- To visualize Amazon Comprehend output using Amazon QuickSight, do the following:
- Connect Amazon QuickSight to Amazon Athena.
- https://docs.aws.amazon.com/quicksight/latest/user/create-a-data-set-athena.html
- https://docs.aws.amazon.com/quicksight/latest/user/managing-permissions.html
- https://aws.amazon.com/blogs/big-data/derive-insights-from-iot-in-minutes-using-aws-iot-amazon-kinesis-firehose-amazon-athena-and-amazon-quicksight/
- Grant Amazon QuickSight access to Athena and the associated S3 buckets in the account. For information on how to do this, see Managing Amazon QuickSight Permissions to AWS Resources in the Amazon QuickSight User Guide.
- Create a new data set for visualising sentiment analysis in Amazon QuickSight based on the Athena table that was created during deployment.
- After setting up permissions, create a new analysis in Amazon QuickSight by choosing New analysis.

- Add a new data set.
- Choose Athena as the source and give the data source a name, such as comprehend_demo.
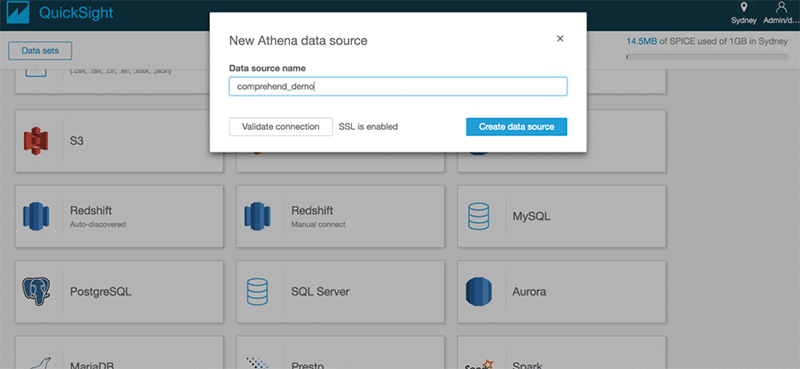
- Click Select to choose the database and table.
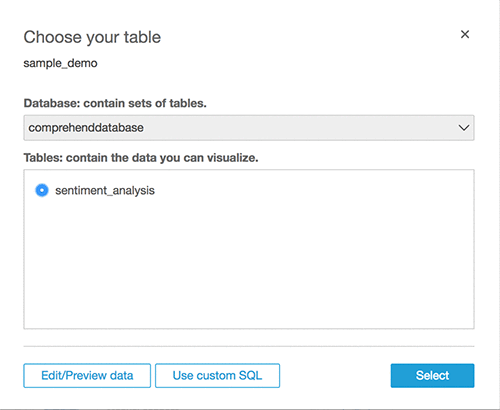
- Click Visualize.
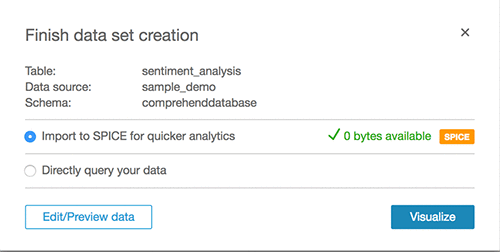
- Create custom visualizations.
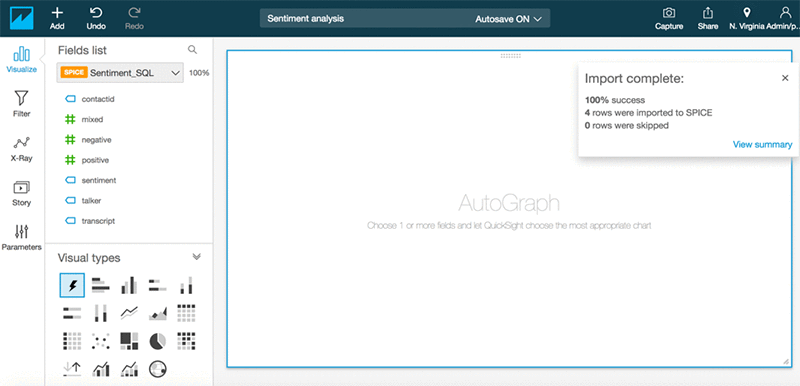
Conclusion
Enterprises can reap significant benefits by realizing the hidden value in the massive amounts of caller-agent audio recordings from their contact centers. By deriving meaningful insights, enterprises can enhance both efficiency and performance of call centers and improve their overall service quality to end customers. So far, we’ve used Amazon Transcribe to transform audio data into text transcripts and then used Amazon Comprehend to run text analysis. Along the way, we’ve also used AWS Lambda and AWS Step Functions to string together the solution. And finally, AWS Glue, Amazon Athena, and AWS QuickSight to visualize the analysis. The AWS CloudFormation templates used to build and deploy this process are available on part 2 of the next post.
In Part 2 of this blog post series we’ll show you how to automate, deploy, and visualize analytics using Amazon Transcribe, Amazon Comprehend, AWS CloudFormation, and Amazon QuickSight.
Source Link: https://aws.amazon.com/blogs/machine-learning/analyzing-contact-center-calls-part-1-use-amazon-transcribe-and-amazon-comprehend-to-analyze-customer-sentiment/