
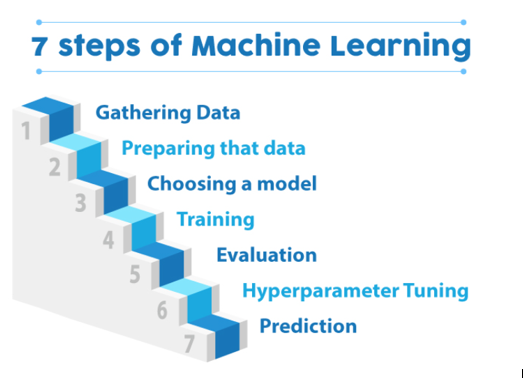
- Gathering Data
This is perhaps the most important and time-consuming process. In this step, we need to collect data that can help us to solve our problem. For example, if you want to predict the prices of the houses, we need an appropriate dataset that contains all the information about past house sales and then form a tabular structure. We are going to solve a similar problem in the implementation part.
- Preparing that data
Once we have the data, we need to bring it in proper format and preprocess it. There are various steps involved in pre-processing such as data cleaning, for example, if your dataset has some empty values or abnormal values (e.g, a string instead of a number) how are you going to deal with it? There are various ways in which we can but one simple way is to just drop the rows that have empty values. Also sometimes in the dataset, we might have columns that have no impact on our results such as id’s, we remove those columns as well. We usually use Data Visualization to visualise our data through graphs and diagrams and after analyzing the graphs, we decide which features are important.
- Choosing a model
Now our data is ready is to be fed into a Machine Learning algorithm. In case you are wondering what is a Model? Often “machine learning algorithm” is used interchangeably with “machine learning model.” A model is the output of a machine learning algorithm run on data. In simple terms when we implement the algorithm on all our data, we get an output which contains all the rules, numbers, and any other algorithm-specific data structures required to make predictions. For example, after implementing Linear Regression on our data we get an equation of the best fit line and this equation is termed as a model. The next step is usually training the model incase we don’t want to tune hyperparameters and select the default ones.
- Hyperparameter Tuning
Hyperparameters are crucial as they control the overall behaviour of a machine learning model. The ultimate goal is to find an optimal combination of hyperparameters that gives us the best results. But what are these hyper-parameters? Remember the variable K in our K-NN algorithm. We got different results when we set different values of K. The best value for K is not predefined and is different for different datasets. There is no method to know the best value for K, but you can try different values and check for which value we get the best results. Here K is a hyperparameter and each algorithm has its own hyperparameters and we need to tune their values to get the best results.
- Evaluation
You may be wondering, how you can know if the model is performing good or bad.What better way than testing the model on some data. This data is known as testing data and it must not be a subset of the data (training data) on which we trained the algorithm. The objective of training the model is not for it to learn all the values in the training dataset but to identify the underlying pattern in data and based on that make predictions on data it has never seen before. There are various evaluation methods such as K-fold cross-validation and many more.
- Prediction
Now that our model has performed well on the testing set as well, we can use it in real-world and hope it is going to perform well on real-world data.
Application in Detecting Skin Diseases using Image Processing
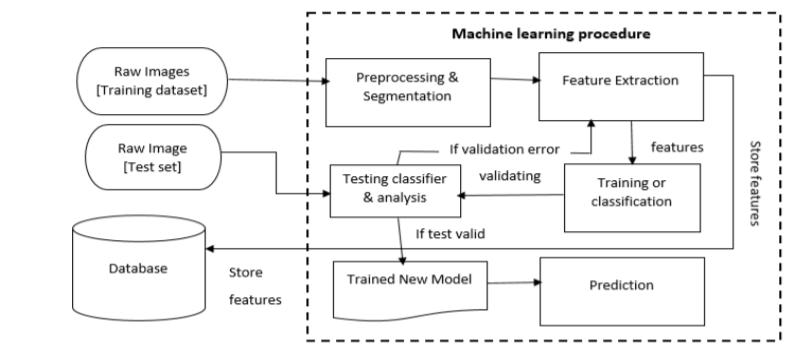
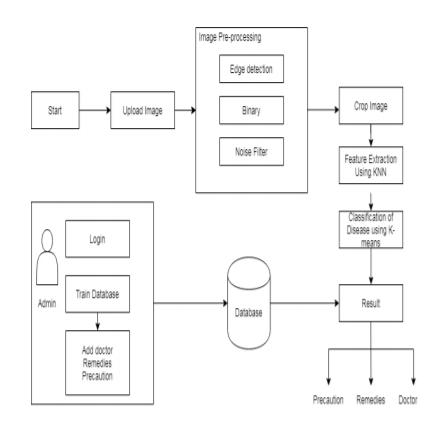
Reference:
https://www.mygreatlearning.com/blog/what-is-machine-learning/
https://www.irjet.net/archives/V7/i6/IRJET-V7I6120.pdf
https://www.ijcaonline.org/archives/volume179/number16/gound-2018-ijca-916253.pdf